The full code implementation described in this blog post can be found at: https://github.com/changjonathanc/vFLUX
Naive implementation
When you ask an AI to write a FastAPI endpoint to serve a PyTorch model, you’ll get something like this:
@app.post("/generate_image")
async def generate_image(request: ImageRequest):
text = request.text
# Generate image
image = pipe(text, num_inference_steps=4).images[0]
# Convert to base64
img_str = post_process(image)
return {"image": img_str}This works fine, but it’s not very efficient when you have multiple requests at the same time.
The PyTorch traces shows a noticeable overhead when running the post_process logic. 
While threading might seem tempting for the post_process logic, it can compete with GPU tasks for GIL and hurt GPU utilization. 1 And using multiple processes can introduce more overhead and complexity.
Utilizing PyTorch Async APIs
By default, GPU operations are asynchronous. When you call a function that uses the GPU, the operations are enqueued to the particular device, but not necessarily executed until later. This allows us to execute more computations in parallel, including operations on CPU or other GPUs. - PyTorch Doc
Analysis of the CPU trace during model inference reveals the following pattern:
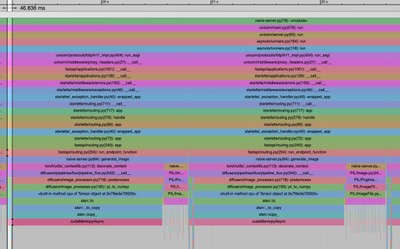
The CPU spends most of its time on cudaMemcpyAsync at the end of model inference. Kernel scheduling for GPU execution takes <50 ms, followed by waiting for GPU execution completion. 2
PyTorch’s Async APIs allow us to free up the CPU while the GPU completes execution. By using the non_blocking=True option and torch.cuda.Event() API, we can efficiently check when results are ready without blocking the CPU.3
# this finishes immediately, but the values are not usable right away
output = images.to('cpu', non_blocking=True)
# when the event is ready, means the previous operation is done
output_ready_event = torch.cuda.Event()
output_ready_event.record(torch.cuda.current_stream())
# we can poll the event until it's ready
while not output_ready_event.query():
await asyncio.sleep(0.001) # yield control flowUsing Semaphore
Now that the CPU is free while waiting for GPU to finish execution, we can use this time to preprocess other requests and schedule their GPU execution.
Here we use a semaphore to allow a second request to schedule kernels, while the current request is still running. 4
semaphore = asyncio.Semaphore(2)
@app.post("/generate_image")
async def generate_image(request: ImageRequest):
async with semaphore:
text = request.text
# Generate image
images = pipe(text, num_inference_steps=4, output_type="pt").images
images = images.to('cpu', non_blocking=True)
output_ready_event = torch.cuda.Event()
output_ready_event.record(torch.cuda.current_stream())
while not output_ready_event.query():
# yield control flow and allow another request to schedule async GPU execution
await asyncio.sleep(0.001)
# Convert to base64
img_str = post_process(images)
return {"image": img_str}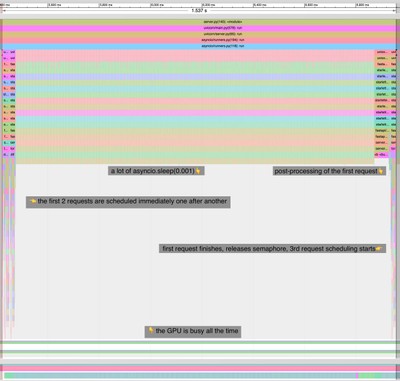
Additional benefits
Because the GPU is still running when the second request is being scheduled, it can hide the CPU overhead in the second request. For example, tokenization is done inside this pipeline before any GPU operations, which normally causes some GPU idle time, but is hidden if GPU is running the previous request at the same time.
Summary
- Make the model inference as asynchronous as possible, use
non_blocking=Trueoption to avoid cuda sync. - Use event to check when the result is ready.
- Use semaphore to allow another concurrent requests to schedule kernels, while the current request is still running.
By keeping the GPU busy, this approach maximizes throughput, which is especially beneficial for offline processing jobs.
Limitations
The pipeline must avoid operations that require CUDA synchronization in the middle. When such operations exist:
- The second request will be blocked from scheduling until the first request completes.
- The first request cannot return results immediately and will have extra latency.
- Overall throughput remains unaffected as long as there are enough requests to keep the GPU busy after the last cuda sync, and the CPU overhead can be hidden.
Command Buffer5 must be large enough to fit at least one request, otherwise scheduling the second request will need to wait for the first one to finish. (This happens to me on H100, but not A100, and I don’t know why)
Lightweight GPU tasks may not fully mask CPU overhead with this single-threaded approach. Profiling is needed to understand the bottleneck.
Tips to avoid cuda sync
One common cause of blocking cuda sync is .to() operation that moves data between CPU and GPU (both directions), it’s important to use non_blocking=True option. Otherwise, it block until all previous instructions are done, even if it doesn’t depend on previous instructions.
This kind of issue can be hard to spot. Because when they are done early in the loop and the sync is fast and hard to notice in the trace. However, in the FastAPI implementation with semaphore, it will show up in the trace when the second request is scheduled before the first one is done. The blocking operation will have to wait for the first request to finish.
Footnotes
Python 3.13 has Free-threaded CPython. https://docs.python.org/3/whatsnew/3.13.html#free-threaded-cpython↩︎
The model is optimized with
torch.compile(model, mode="max-autotune")↩︎I learned the PyTorch Async API from vLLM’s implementation of asynchronous output processing: https://blog.vllm.ai/2024/09/05/perf-update.html↩︎
We use Semaphore(2) since we only need to overlap one executing request with one scheduled request - any more concurrent requests wouldn’t improve throughput as the GPU can only execute one kernel at a time.↩︎
Command Buffer behavior is sparsely documented. The most recent mention in the doc seems to be CUPTI doc↩︎