Jonathan Chang - Personal Website

Projects
Featured
LLMProc
A Unix-inspired framework for building robust, scalable LLM applications
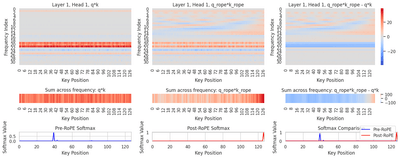
Additive Rotary Embedding
A competitive variant of rotary position embedding (RoPE)
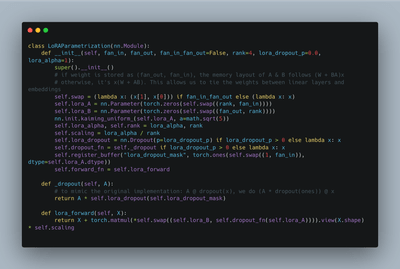
minLoRA
A minimal library for LoRA (200 LoC!), supports any model in PyTorch
Notable
kodx
Kodx
Docker-based AI coding agent inspired by GitHub Copilot Codex
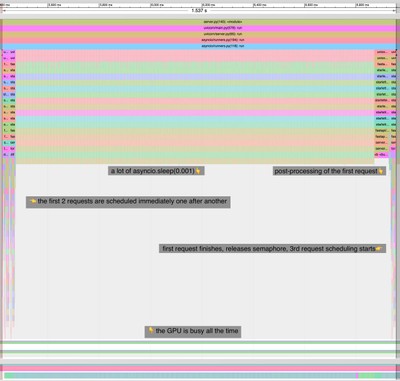
vFLUX
An optimized FLUX model inference engine
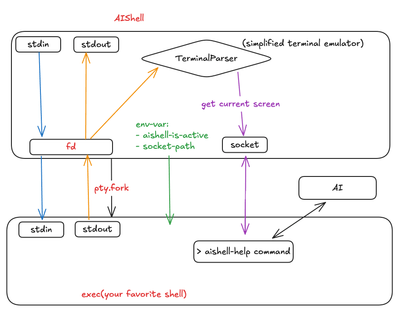
AI Shell
A transparent shell wrapper for building context-aware AI tools
Anim·E
State-of-the-art anime image generator at the time, before Stable Diffusion fine-tuned models
More

Claude Code System Prompts
A website that shows Claude Code's system prompts across different versions
wikimcp
WikiMCP
A MCP server to let Claude explore random Wikipedia pages
uvx llmcp serve
LLMCP
A minimal MCP server for LLM to query other LLMs via LiteLLM and MCP.
fork()
Forking an AI Agent
A MVP exploring fork() pattern for AI agents
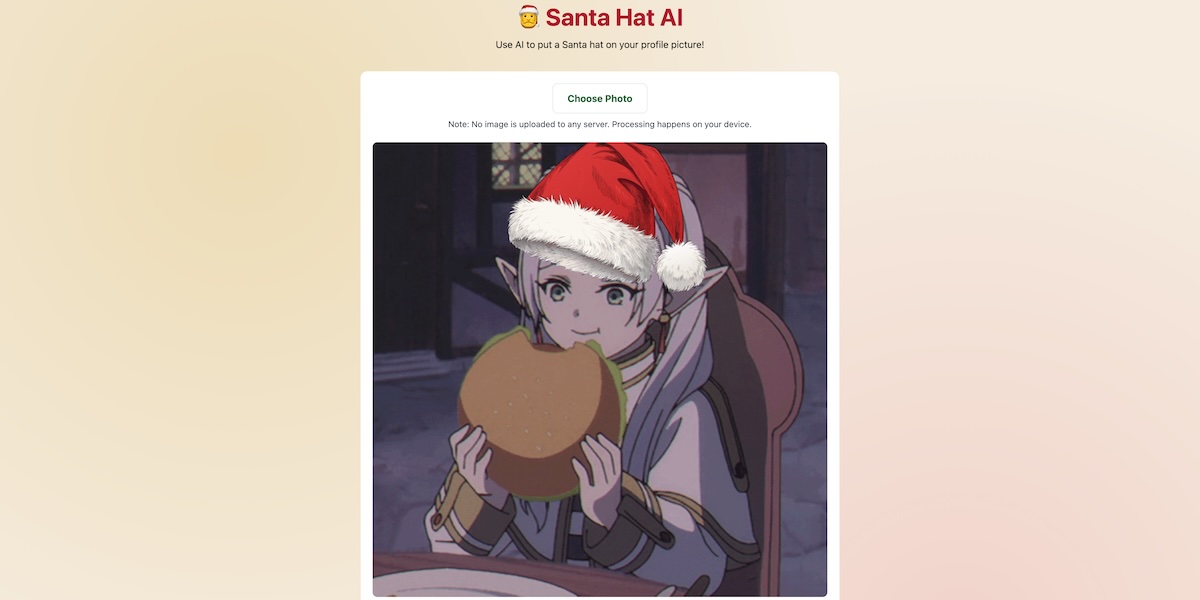
Santa Hat AI
A webapp that uses MediaPipe face detection to automatically place festive santa hats on profile pictures
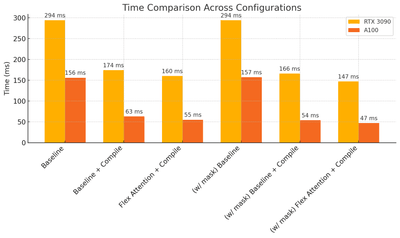
T5 FlexAttention
T5 model optimized with FlexAttention
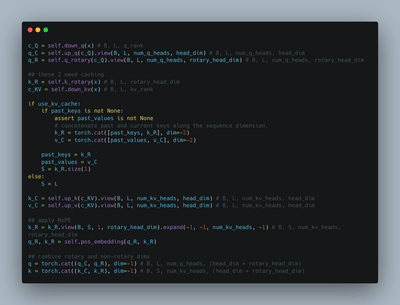
Multi-head Latent Attention
I implemented Multi-head Latent Attention from deepseek-v2
Mixture of Depths
I implemented Mixture of Depths from Google DeepMind's paper

Flex Diffusion
I fine-tuned Stable Diffusion 2 for dynamic aspect ratio generation

DDIM inversion notebook
My popular notebook demonstrating DDIM inversion using Stable Diffusion
Publications
Timeline
2022 - 2024 · Taboola
Spend some time working in algorithm team, worked on feature engineering and designed experiments. Later joined the Generative AI team, where I integrated and optimized SoTA image models into our product.
2021-2022 · BigScience Project
I contributed to the BigScience project, mainly in the metadata working group. I worked on the training codebase and conducted research experiments on using metadata to improve language model performance.
2021-2022 · ASUS AICS
I spent 6 months in the AICS department, where we collaborated with local hospitals. I worked on medication recommendation models using BERT.
2020-2021 · NTU MiuLab
I worked with Prof. Yun-Nung Chen on SoTA Dialogue System based on GPT2. We participated in the Situated Interactive MultiModal Conversations (SIMMC) Challenge (DSTC9) and achieved 3rd place.
2020 · Google
Spent a summer at Google, internship was replaced with a remote project due to COVID-19. I worked on a project using NLP to recommend relevant articles to users.
2017-2021 · National Taiwan University
Completed my undergraduate studies in Computer Science, focusing on machine learning and artificial intelligence. I was a TA for the course Applied Deep Learning.