Introduction
This blog post documents the flex-nano-vllm project and attempts to linearize the reasoning process of writing a vLLM inference engine from scratch. This post also discusses tradeoffs of different implementation decisions and experiments that did not end up in the final codebase.
Understanding FlexAttention BlockMask
This section explains how
BlockMaskworks under the hood, complementing the PyTorch blog post. Consider reading that first for context.
Before implementing paged attention, we need to understand BlockMask. I find the existing documentation scattered across different places, so here’s my attempt at a unified explanation. You can also find the official doc here.
What is a BlockMask?
Here I’ll try to explain BlockMask using the examples from the above blog post. During inference, BlockMask is simply an abstraction that holds the following attributes:
seq_lengths: tuple[int, int]
kv_num_blocks: Tensor
kv_indices: Tensor
full_kv_num_blocks: Optional[Tensor]
full_kv_indices: Optional[Tensor]
BLOCK_SIZE: tuple[int, int]
mask_mod: _mask_mod_signatureIf you print out the shapes of these attribute you’ll see they look like this:
kv_num_blocks: torch.Size([B, H, Q_LEN//128])
kv_indices: torch.Size([B, H, Q_LEN//128, KV_LEN//128])
full_kv_num_blocks: torch.Size([B, H, Q_LEN//128])
full_kv_indices: torch.Size([B, H, Q_LEN//128, KV_LEN//128])note: B and H could be 1 if the mask is agnostic to the batch or head dimension. And 128 is the default block size. You can manually specify block size when creating a block mask.
Now let’s look at an example from the blog post: 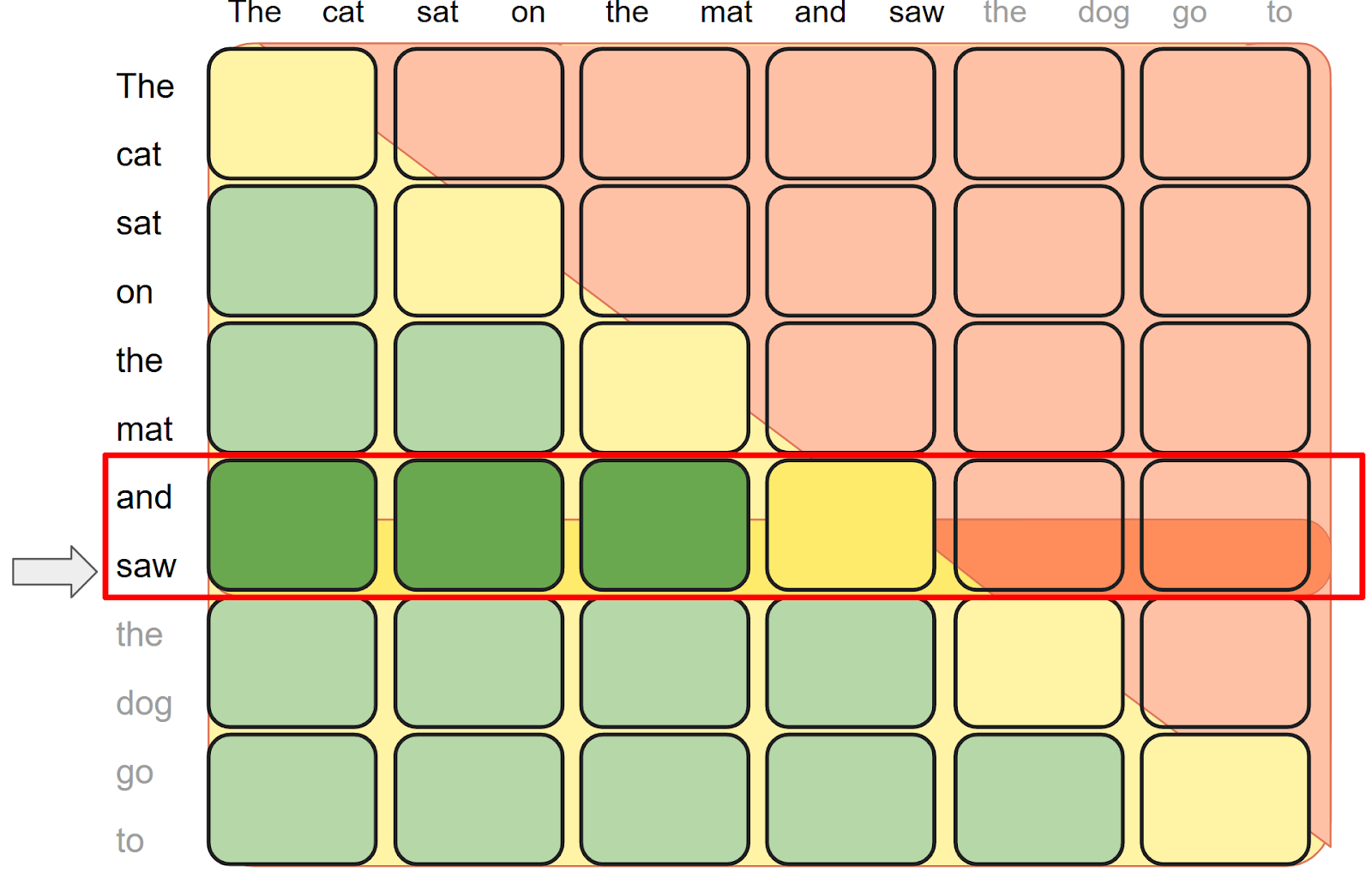
In this image, we have:
seq_lengths = (12, 12)
BLOCK_SIZE = (2, 2)
mask_mod = lambda b,h,q,kv: q>=kv
# partial blocks
kv_num_blocks = tensor([1,1,1,1,1,1]).view((1,1,6))
kv_indices = torch.tensor(
[0, _, _, _, _, _],
[1, _, _, _, _, _],
[2, _, _, _, _, _],
...
).view((1, 1, 6, 6))
# full blocks
full_kv_num_blocks = tensor([0,1,2,3,4,5]).view((1,1,6))
full_kv_indices = torch.tensor(
[_, _, _, _, _, _],
[0, _, _, _, _, _],
[0, 1, _, _, _, _],
...
).view((1, 1, 6, 6))
# values marked _ means undefined, and will be ignoredWhich can be summarized as follows:
- full blocks: stored sparsely in
full_kv_num_blocks/full_kv_indices - empty blocks: not explicitly stored, and is skipped during flex attention
- partial blocks: stored sparsely in
kv_num_blocks/kv_indices, callsmask_modat runtime to compute the actual mask.
note: score_mod is not part of BlockMask. If you want to modify attention score (e.g. logit softcap), you can pass it independently to
flex_attention(query, key, value, score_mod=None, block_mask=None, ...)
Creating BlockMasks Manually
In most use cases, you use create_block_mask to create a block mask. But you can potentially create it faster, if you know how to create it manually. This is because create_block_mask needs to go through all q_idx and k_idx to determine if each block is partial/full/empty, it can take a long time for long sequences. You can find examples in attention-gym and KellerJordan/modded-nanogpt.
Slicing BlockMasks
In the PyTorch blog post and in gpt-fast, you can find the following code used during decoding to reuse/slice an existing block mask for each decoding step:
block_offset = i // block_mask.BLOCK_SIZE[0]
block_mask_slice = block_mask[:, :, block_offset] # <- BlockMask.__getitem__
block_mask_slice.mask_mod = get_mask_mod(causal_mask, offset=input_pos[0])I find this a little confusing, because a BlockMask is not an actual tensor, why can you slice it? But under the hood it’s just a simple wrapper for creating a new BlockMask object based on the block indices.
See BlockMask.__getitem__
def __getitem__(self, index) -> "BlockMask":
new_kv_num_blocks = self.kv_num_blocks[index]
new_kv_indices = self.kv_indices[index]
if self.full_kv_num_blocks is not None:
assert self.full_kv_indices is not None
new_full_kv_num_blocks = self.full_kv_num_blocks[index]
new_full_kv_indices = self.full_kv_indices[index]
else:
new_full_kv_num_blocks = None
new_full_kv_indices = None
return BlockMask.from_kv_blocks(
new_kv_num_blocks,
new_kv_indices,
new_full_kv_num_blocks,
new_full_kv_indices,
BLOCK_SIZE=self.BLOCK_SIZE,
mask_mod=None,
seq_lengths=self.seq_lengths,
compute_q_blocks=self.q_indices is not None,
)
TIP: You can simply avoid this syntax and construct the new block mask manually.
Now that we understand BlockMask mechanics, let’s implement our vLLM engine.
Building flex-nano-vllm
Our goal is to implement a generate() interface that takes any number of requests, batches them dynamically, and generates outputs efficiently. And to efficiently batch the requests, we need a Paged Attention.
Paged Attention Implementation
To simplify things, we build a minimal page table without prefix sharing between requests, which means there’s no need for hashing or complex reference counting. And we’ll start with the code in attention-gym.
First we focus on decoding. We’ll discuss pre-filling later.
In normal flex attention decoding, the input to flex_attention have the following shape: (only batch size or sequence lengths related dimensions are shown here)
- query:
(B=B, L=1) - key & value:
(B=B, L=max_seq_len) - block_mask:
(B=B, Q_LEN=1, KV_LEN=max_seq_len)
But paged KV cache have this shape: (B=1, L=num_pages*page_size), do we need to broadcast the batch dimension to pass it into flex_attention? Turns out we don’t! We can pass the following to flex_attention (this is not well documented outside of the source code):
- query:
(B=B, L=1) - key & value:
(B=1, L=num_pages*page_size) - block_mask:
(B=B, Q_LEN=1, KV_LEN=num_pages*page_size)
In other words, we can directly pass the query and the paged KV cache tensor to flex_attention, and use the block mask to make it compute attention only on the correct positions. nice.
To construct the block mask, we need a page table. The key attributes of page table are simple, only 2 tensors are needed, plus a few variables for tracking the allocation of pages.
page_table # [logical_batch_idx, logical_block_idx] -> physical_page_idx
physical_to_logical # [logical_batch_idx, physical_page_idx] -> logical_page_idxWe use a simple method to construct the block mask:
- Create a usual logical block_mask:
[B, H, 1, logical_kv_max_seq_len] - Using the page table, convert the logical block_mask to a physical block mask:
[B, H, 1, physical_kv_max_seq_len]. This is defined inconvert_logical_block_mask.
NOTE: This interface design makes it easier to add/compare paged attention to existing code. You can technically skip the 2 step process and construct the final block mask directly.
class PageTable:
def convert_logical_block_mask(
self,
block_mask: BlockMask,# [B, H, 1, logical_kv_max_seq_len]
batch_idx: Tensor, # [B]
) -> BlockMask: # [B, H, 1, physical_kv_max_seq_len]
...
flex_attention(
q, # (L=1, B=B)
paged_k_cache, # (L=num_pages*page_size, B=1)
paged_v_cache, # (L=num_pages*page_size, B=1)
block_mask = page_table.convert_logical_block_mask(logical_block_mask, batch_idx)
...
)The conversion requires the above 2 tensors for mapping:
page_table(logical to physical) is used to map kv_num_blocks, kv_indices to the physical address in the paged KV cache.physical_to_logicalis used to convert themask_mod: During inference,mask_modwill be called with physical index(b,h,q_idx,kv_idx). We need to convert it to logicalkv_idxand call themask_modin the original block_mask
IMPORTANT: we also need to map
bto logical batch idx, this is missing in the attention-gym implementation, but present in vllm’s flex attention backend implementation.
Updating paged KV cache
At each decoding step, before calling flex_attention with the kv cache, we need to update the KV cache with the new position’s values. Updating the paged KV cache assumes the following interface:
k_cache, v_cache = kv_cache.update(k, v, input_pos, batch_idx)the input/output have the following shapes:
- k & v:
(B=B, L=1) - k_cache & v_cache:
(B=1, L=num_pages*page_size) - input_pos:
[B, 1] - batch_idx:
[B]
The conversion is simple: use a page_table mapping [logical_batch_idx, logical_block_idx] -> physical_page_idx to convert the index and assign the new kv to the paged cache.
Pre-filling Strategy
When implementing a new inference code from scratch, single sequence pre-filling is useful for identifying bugs in the code by comparing the output with a simple forward() call.
You can use this to test the PageTable implementation by following the same steps above:
- construct a logical block mask
(B=1, Q_LEN=L, KV_LEN=L) - convert it to
(B=1, Q_LEN=L, KV_LEN=num_pages*page_size), by callingconvert_logical_block_mask - assign k/v to k_cache/v_cache
- call flex_attention with
(q, k_cache, v_cache, converted_block_mask)
But if we don’t use prefix sharing, we can call flB=B, L=ex_attention with (q, k, v, block_mask) without conversion. Additionally, we can implement document packing for batched pre-filling by using the same block_mask used during training. Note that we still need to assign k/v to k_cache/v_cache. This is the current solution in the flex-nano-vllm repo.
Dynamic Batching & CUDA Graphs
So far we haven’t discussed how to efficiently process a large number of requests that can’t be processed all at once. And when we decode multiple requests, some might end earlier than others, we should be able to free the space and pick up the next waiting request to process.
Let’s start with a simple implementation: for each new request, allocate space for (input_length + max_output_length). This way we don’t need to dynamically allocate new pages during generation. We’ll revisit this later.
So now each decoding step may have varying number of requests, depending on how many requests are available and how many can fit in the page table. This requires dynamically allocating intermediate tensors, and a lot of CUDA kernel launches. We can use CUDA graphs to speed this up.
This optimization technique is well-documented in other places, so I won’t go into detail here. It’s best to read the source code directly to understand it. The code was adapted from nano-vllm.
To briefly describe it: we warm up the model and capture a set of CUDA graphs, each supporting a fixed batch size, and during decoding, we pad the input to the smallest batch size with a CUDA graph, and replay the graph.
Experiments & Notes
- The nano-vllm captures CUDA graphs for batch size increment of 16, while vllm does it with 8-increment. I tried both and found negligible performance differences. So I used 16 for fewer capturing steps and overhead.
- You can do graph capture for prefill, too. But I found it to only result in minor end to end speed up (most wall clock time is spent in decoding steps). I removed it to keep the code simpler.
- During graph replay, to make sure that the padded position does not overwrite any pages that are in-use, or cause out of bound indexing, I reserve batch_idx=0 and page_idx=0 for padding.
Memory Management & Preemption
Turns out pre-allocating all the pages needed is not optimal: the model can reach EOS before max_output_tokens is reached. And we waste reserved space that could have been used to serve another concurrent request.
And to support dynamic allocation, we need to support preemption: when the running sequences grow longer, we might run out of pages and need to preempt some request. Preemption means we’ll need to recompute the kv cache of some sequences, but the benefit of larger decoding batch size often outweighs the cost of supporting higher concurrency during decoding steps.
Testing & Validation
Testing correctness is crucial when building inference engines from scratch. Here are the validation steps I used for flex-nano-vllm:
- Pre-fill: test the output matches Hugging Face reference implementation, as described above. This ensures paged attention & flex attention are correct.
- Small batch sampling: tests the greedy decoding output matches Hugging Face
generate()implementation. One tricky thing is that sometimes even numerical differences can cause slight divergence in output (I noticed some differences with flex attention after switching from single sequence pre-filling to batched pre-filling), so I iterated and chose inputs that have unambiguous continuation, and test only the first few output tokens. - Test consecutive generate() calls produce the same results: this tests the page and batch idx management are correct. There was a subtle but critical bug that caused the output to differ in later
generate()calls: Because the batch_idx allocated to each sequence might not be in-order, the mask_mod needs to know the actual batch_idx so it can index the correct page table entry.
Performance Results
After implementing and testing our system, here’s how it performs compared to production vLLM. (You can find more implementation details in the repo.)
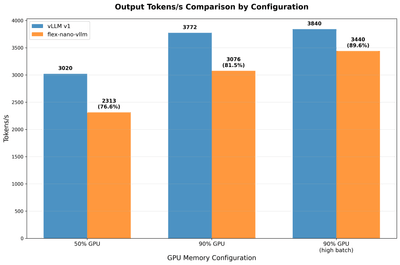
On the right most bars, the high batch config allows concurrency to be equal to the number of requests, meaning there’s no preemption and most performance difference can be explained by the cpu overhead and kernel performance. Inspecting the torch profiler trace shows the CPU overhead causes the GPU to be idle ~4% of the time.
On the middle and on the left, the performance difference can be explained by this chart:
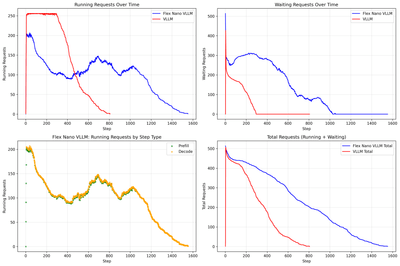
In vLLM v1, a single step can process decoding and pre-filling at the same time. While flex-nano-vllm requires a lot of separate pre-filling steps (green dots on the bottom left), significantly increasing the number of steps required.
Conclusion
With ~1000 LoC, flex-nano-vllm matches 90% of vLLM’s performance in the best case, and you can easily adapt it to any architecture that isn’t supported by vLLM. Flex-nano-vllm also supports passing in a live model instance, which means you don’t need to make a copy of the model to run inference when doing online reinforcement learning.
Future work
To close the performance gap, implementing unified pre-filling and decoding seems necessary. Other features like prefix caching/sharing, multi-GPU inference demonstrated in nano-vllm are not implemented in flex-nano-vllm.