Preprint: this blog post is partially written by codex, I plan to update this post later once I have more results.
Intro
I was doing some small MoE experiments and realized how hard MoE load balancing is. I tried DeepSeek-V3 style aux-loss-free balancing, and also the momentum-based aux-loss-free variant from Trinity Large. Then Jianlin Su’s Quantile Balancing (QB) came out.
QB worked like advertised initially, but perhaps due to some bugs in my earlier code, it did not work well enough. I spent some time thinking about it, and identified two issues that QB does not solve.
- Inter-example noise. QB estimation depends on batch statistics, which has inherent noise. Larger batch size helps reduce the estimation error, but a batchwise bias does not guarantee that each sequence is balanced. DeepSeek also uses a small per-sequence load balancing aux loss, despite using aux-loss-free bias.
- Inter-batch parameter drift. The quantile bias is estimated on one step and applied to the next, while the router parameters have already changed. This is less of an issue after you anneal the model, but the issue exists during training.
In my own runs, QB clearly helped, but max_vio still had pretty large step-to-step swings. That motivated the main idea here: Causal Bias (CB).
Expert choice breaks causality. QB deals with that by estimating a bias on one batch and applying it to the next. What if we can calculate a bias within each sequence without violating causality, and apply it immediately?
Heuristic Causal Bias (CB)
This was the first thing I tried. The idea is simple: if an expert has been getting a lot of score mass recently inside the current sequence, push it down a bit for the next tokens in that same sequence.
The Update Rule
Let s_t = \sigma(z_t) \in \mathbb{R}^N denote the router scores at token t, where N is the number of experts. The kernel maintains a carry vector and exposes a pressure vector p_t used to route token t:
p_t = \begin{cases} 0, & \text{if token } t \text{ starts a new sequence} \\ c_{t-1}, & \text{otherwise} \end{cases}
c_t = \gamma \cdot p_t + s_t
The routing decision at position t uses a penalized score:
\tilde{s}_t = s_t - \lambda \cdot p_t
\text{selected}_t = \text{top-}k(\tilde{s}_t)
Equivalently, written only in terms of the pressure state:
p_t = (1 - b_t)\left(\gamma \cdot p_{t-1} + s_{t-1}\right)
where b_t \in \{0, 1\} is the sequence-start mask. This is the math implemented in the kernel: reset on sequence start, otherwise reuse the previous carry, then update the carry with the current token’s score.
The pressure path is stop-gradient: it never pollutes the router’s quality gradient.
Steady State and a Natural Default for λ
Away from sequence boundaries, if the scores are approximately stationary, pressure converges to:
p^* = \gamma \cdot p^* + s \implies p^*(1 - \gamma) = s \implies p^* = \frac{s}{1 - \gamma}
The penalty applied to a dominant expert at steady state is:
\lambda \cdot p^* = \lambda \cdot \frac{s}{1-\gamma}
If we want this penalty to stay on roughly the same scale as the sigmoid scores themselves, a natural scale-matching choice is \lambda / (1-\gamma) \approx 1, giving:
\boxed{\lambda = 1 - \gamma}
I use this as a good default rather than a separate tuned hyperparameter. Once \gamma is chosen, \lambda = 1 - \gamma keeps the penalty on a reasonable scale.
The only remaining design choice is \gamma: a higher \gamma means a longer memory, while a lower \gamma forgets faster.
A good default is \gamma = 0.9, corresponding to a half-life of \approx 7 tokens.
Sequence Boundary Handling
One implementation detail that matters is sequence boundaries. When multiple sequences are packed into one row, the scan update needs to be masked at sequence starts. Otherwise different sequences would interact with each other through the carry state, which creates an unnecessary train-test gap and breaks the intended causal interpretation.
Time Complexity and Parallelism
CB requires a scan-like recurrence along the sequence dimension. This can be rewritten as an efficient associative scan with O(log T) depth, and I did try PyTorch’s torch.associative_scan for that path. However, in my setting it was slower than a direct linear Triton implementation, and PyTorch also currently documents torch.associative_scan as a prototype feature that requires torch.compile, lacks autograd support, and may miscompile.
So in practice I just use a direct Triton backend for the recurrence. Its dependency depth is still O(T) per batch row with O(N) work per token.
Compatibility with Quantile Balancing
QB can be applied on top of CB. In practice, CB+QB turns out to be a strong baseline: CB reduces local causal imbalance, and QB cleans up the residual batch imbalance.
Causal Dual Bias (CDB)
CB was useful, but one of my earlier training runs also exposed a real weakness of it. Due to a bug, CB collapsed badly in that run. The bug itself was fixable, but it made the underlying limitation more obvious: CB is applied to the scores before the top-k decision, so it can only nudge routing indirectly. It does not update from the actual selected experts, and it does not come with any real balance guarantee. It is fundamentally a heuristic.
At that point I wanted something more principled, something more like QB. So I asked Claude to help me with the math.
From QB to an Online Update
The natural question is: what’s the causal version of QB’s LP? At each step t, you’re solving:
\max \sum_j x_{tj} \cdot s_{tj}
subject to
\sum_j x_{tj} = k
\sum_{\tau \le t} x_{\tau j} \approx tk/n
This is an online linear program. The standard tool is online dual descent on the Lagrangian. The dual variable \beta_j would update as:
\beta_j \leftarrow \beta_j - \eta_t \cdot (x_{tj} - k/n)
- Claude
That was the key idea. The sign convention there is opposite to mine. Since I route with s_t - \beta_t, I write the update with a plus sign:
x_{tj} = \begin{cases} 1, & \text{if expert } j \text{ is selected at token } t \\ 0, & \text{otherwise} \end{cases}
with
\sum_{j=1}^{N} x_{tj} = k.
The target usage per token is k/N per expert. CDB maintains a per-sequence dual variable \beta_t \in \mathbb{R}^N, resets it at sequence boundaries, and routes with
\tilde{s}_t = s_t - \beta_t.
Then, after selecting top-k, it updates
\beta_{t+1,j} = \beta_{t,j} + \eta \left(x_{tj} - \frac{k}{N}\right).
Operationally, this is:
- Route using s_t - \beta_t.
- Subtract \eta \cdot k/N from all experts.
- Add \eta back to the selected experts.
- Reset \beta when a new sequence starts.
I call it Causal Dual Bias (CDB). It is the causal, per-sequence counterpart to QB’s batchwise dual bias. Algorithmically, it is just an online dual-descent update.
A good intuition here is that \beta is proportional to cumulative imbalance. That is what this state is really tracking. Unlike CB, CDB updates from realized routing decisions rather than a score EMA. Unlike QB, it is fully causal inside a sequence.
The main extra hyperparameter here is the step size \eta. In practice it does not seem extremely sensitive, but if it is too large it can produce flip-flop behavior.
Computation Cost
CDB is also more expensive to compute than CB or CB+QB in the current implementation.
The reason is structural. CB keeps the causal recurrence simple and applies top-k after the scan. CDB instead has to route with s_t - \beta_t and then update \beta_t from the actual selected experts, so top-k now sits inside the recurrent loop.
I implemented a Triton kernel for CDB and benchmarked it against the existing CB path. In routing-side microbenchmarks matching this setup, the current Triton CDB kernel was still slower than the existing CB+QB path (cb_scan_triton + top-k + QB estimate): roughly 1.7x slower than the uncompiled CB+QB route and about 2.2x slower than a compiled CB+QB proxy.
That said, routing is only a small fraction of end-to-end training time. In the corresponding nanochat configuration, the estimated overall step-time increase was only around 1%. So the routing microbenchmark is clearly worse, but the full training-step cost still looks manageable.
Empirical Results
There are two useful ways to look at this:
- Post-hoc tradeoff plots on a TinyStories proxy.
- Live small-scale nanochat runs that directly measure
max_vioduring training.
Post-hoc Tradeoff
I built a TinyStories proxy with seq_len = 2048, batch_size = 8, and 8 train / 8 eval microbatches per step-sized window, for 131k tokens on each side. Even though the context length is 2048, the average sequence segment length in this setup was still around 660 tokens, which is already long enough for CDB to mostly settle within a sequence.
I carried QB state across steps and compared the methods by:
- per-sequence load sigma
- batch load sigma
- batch
max_vio - score retention, defined by the sum of selected raw sigmoid scores relative to no-bias top-k
The post-hoc picture is that CB+QB is a strong practical baseline and looks very attractive in the tradeoff:
- QB is clearly improved by adding CB.
- CB+QB gets much lower noise than QB for only a modest extra retention cost.
- CDB is interesting, but in this post-hoc frontier it is not obviously dominant.
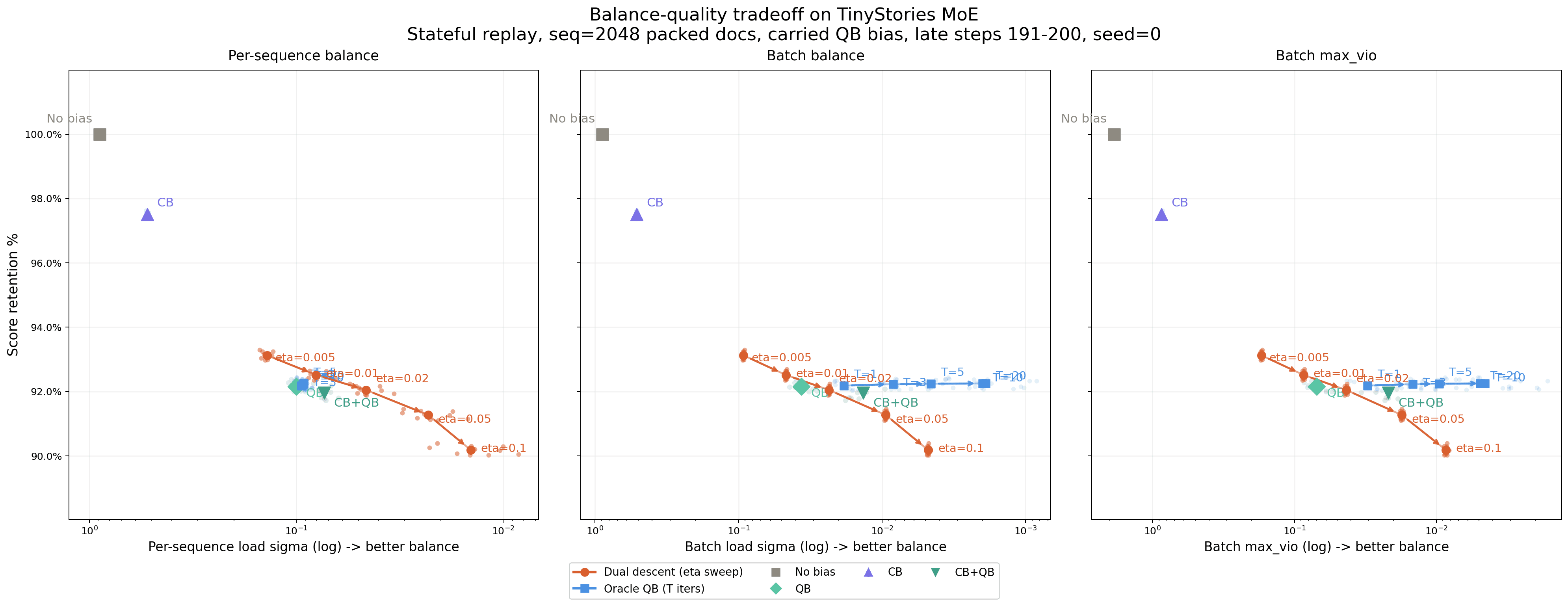
Based on this replay-based post-hoc simulation, CB+QB looks like the most attractive practical method. However, in actual training runs, I found that CDB can drive max_vio much lower.
This is still a frozen-logit routing diagnostic, not a direct measure of model quality. Better score retention does not necessarily imply better training loss or better final performance. Persistent-bias methods such as QB may also be easier for the model to absorb as a background offset than dynamic causal controllers such as CB or CDB. At the scale I have run so far, the loss curves are too similar to draw a strong conclusion about the quality tradeoff.
Live Nanochat Training Runs
Actual training tells a somewhat different story.
In small live nanochat runs, both CDB / dual descent with \eta = 0.05 and CDB / dual descent with \eta = 0.01 drive max_vio far below QB or CB+QB.
The strongest result so far is not from the post-hoc figure but from live training:
- QB has the highest tail imbalance.
- CB+QB is much better than QB.
- CDB converges to another order of magnitude lower
max_vioin the small runs so far.
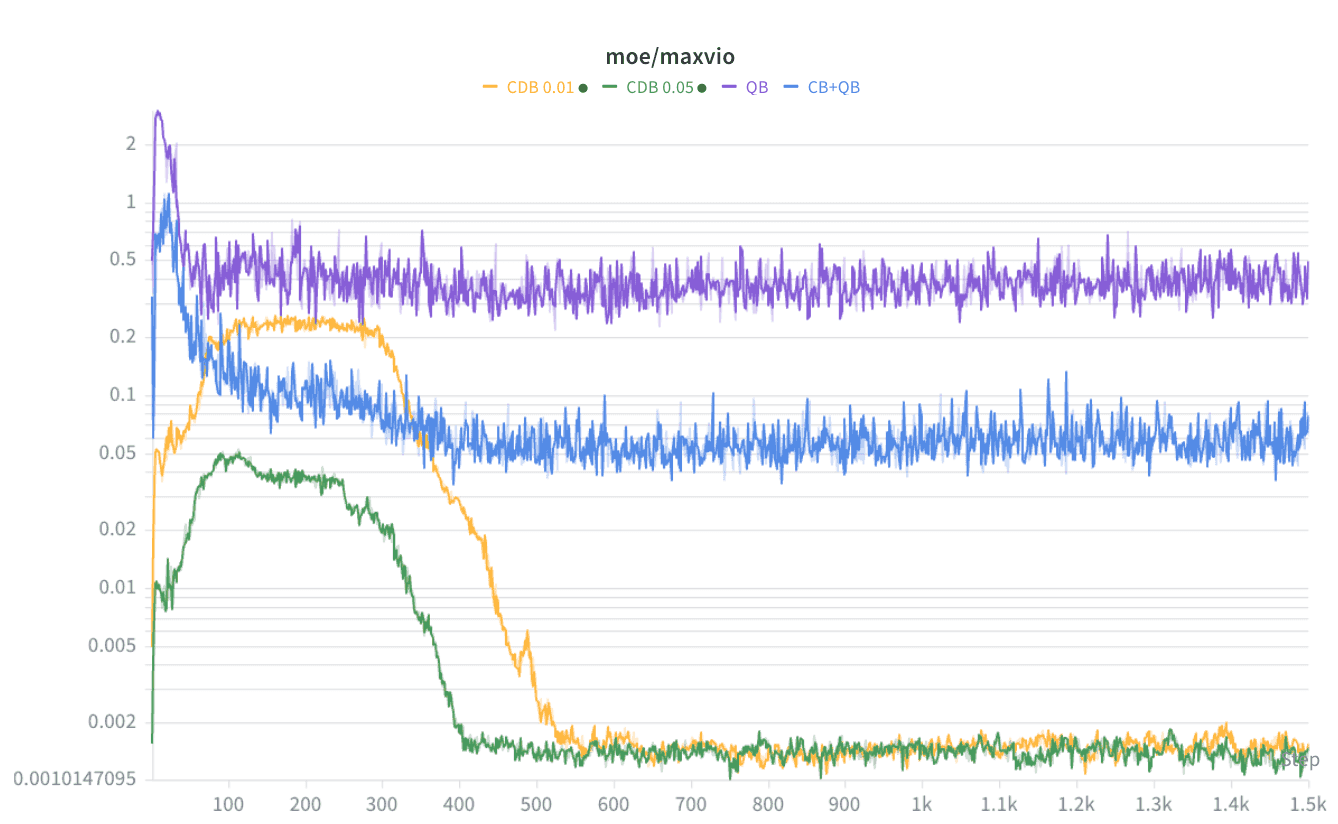
moe/maxvio from small training runs. QB stays highest, CB+QB is much lower, and CDB with both eta=0.01 and eta=0.05 eventually converges to another order of magnitude lower tail imbalance.So my current view is:
- CB is the useful heuristic causal idea.
- CB+QB is a strong practical baseline.
- CDB is the principled causal alternative, and its strongest evidence currently comes from live training rather than post-hoc replay.
What Is Still Unresolved
The main unresolved question is still quality.
At the small scale I can currently afford, the loss curves are all very close, so they are not strong enough to resolve the quality tradeoff between CB+QB and CDB. Right now the evidence is much stronger on balance, especially tail imbalance, than on final model quality.
Conclusion
What I wanted to do in this post was propose a broader class of router-side controllers: causal routing bias.
QB is a principled batchwise method. In the idealized limit where it achieves exact balance, it is optimal for that constrained problem: maximize total score subject to perfect batch-level balance. But in practice, QB is approximate and stale. Once we leave the exact-balance limit, there is room for other potentially better practical tradeoffs between balance and total score.
The current evidence is not yet conclusive. At the scale I have run so far, the loss curves are too close to settle the quality tradeoff.
I also suspect that per-expert balance is not always the most useful final objective. Once expert-level imbalance is already low enough that dead experts are unlikely, the improvement is more about training throughput than training stability. In a real distributed MoE, experts are owned by devices. For example, with 256 experts sharded across 8 GPUs, each GPU owns 32 experts. At that point, what matters operationally is not whether every expert has exactly equal load, but whether any owner becomes the throughput bottleneck.
That suggests a different optimization target: minimize overload at the owner level. Let g(j) be the owner of expert j, and define owner load
O_g = \sum_t \sum_{j : g(j) = g} x_{tj}.
If there are M routed tokens and k experts per token, then the average owner load is
\bar{O} = \frac{Mk}{G},
where G is the number of owners. The owner-level problem is then
\max_x \sum_{t,j} x_{tj} s_{tj}
subject to
\sum_j x_{tj} = k \quad \forall t
and
O_g \le (1 + \rho)\bar{O} \quad \forall g,
for some allowed owner overload \rho.
The dual of this problem is simple: place one dual variable \mu_g on each owner, and route with
\tilde{s}_{tj} = s_{tj} - \mu_{g(j)}.
If an owner is overloaded, all experts on that owner get pushed down together. The corresponding online update is an owner-level dual step. If
z_{tg} = \sum_{j : g(j) = g} x_{tj}
is the number of selected experts on owner g for token t, then one natural update is
\mu_g \leftarrow \left[\mu_g + \eta_{\text{owner}}\left(z_{tg} - \frac{k}{G}\right)\right]_+.
This directly targets the quantity that determines throughput: owner overload, not expert symmetry.
One possible design is a hierarchical bias scheme, similar to DeepSeek’s grouped routing idea: a coarse owner-level bias to optimize owner-level balance, combined with a weaker expert-level bias to prevent dead experts and encourage healthy specialization within each owner.